🐍 A simple web scraper Telegram bot using Python
AUTOMATE BORING STUFF
Automating annoying stuff is essentially what developers do for themselves and others everyday. An example of annoying stuff for me was to check on the web the meaning of words while I was reading a slightly difficult book. It was really frustrating to browse the web every time. Then I had the idea: create a Telegram bot that sending a word sends back a message with its pronunciation and meaning.
I started by looking for a dictionary REST API with the purpose of reusing a simple Node.js project that I have developed one year ago but I was not able to find any free dictionary API service. With this in mind, I understood that web scraping was the right way.
WHAT IS WEB SCRAPING AND WHY USE PYTHON
Web scraping is a technique used to extract data from websites. It could be really useful and powerful. An example could be a program that notifies you when a new Thinkpad appears on Ebay or when the price of a product in your Amazon wishlist decreases.
Actually I have tried to develop an Amazon price tracking service but, unfortunately, Amazon has a vested interest in protecting its data and some basic anti-scraping measures in place. It’s possible to avoid bot detection but it needs a lot of effort, hundreds of proxy servers, and honestly I do not really like the cost benefits.
I used Python because it is easy to use and read, and, not only in my opinion, the best tool to develop a web scraping program.
LET’S START SCRAPING
In order to start scraping the web we have to create a Python project and import the following libraries: requests for HTTP requests, pprint to prettify our debug logs and BeautifulSoup, we will use it to parse HTML pages.
import requests
from pprint import pprint
from bs4 import BeautifulSoupOnce we have installed and imported our libraries, the first thing we have to do is define a function that will replicate the following user behavior:
- Browse a dictionary website.

- Search for the unknown word and start reading the word meaning in the page result.
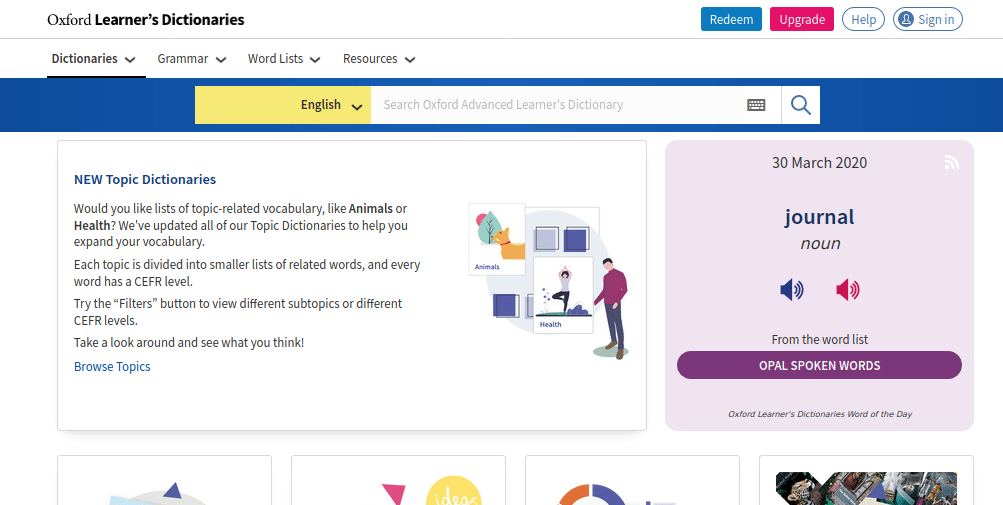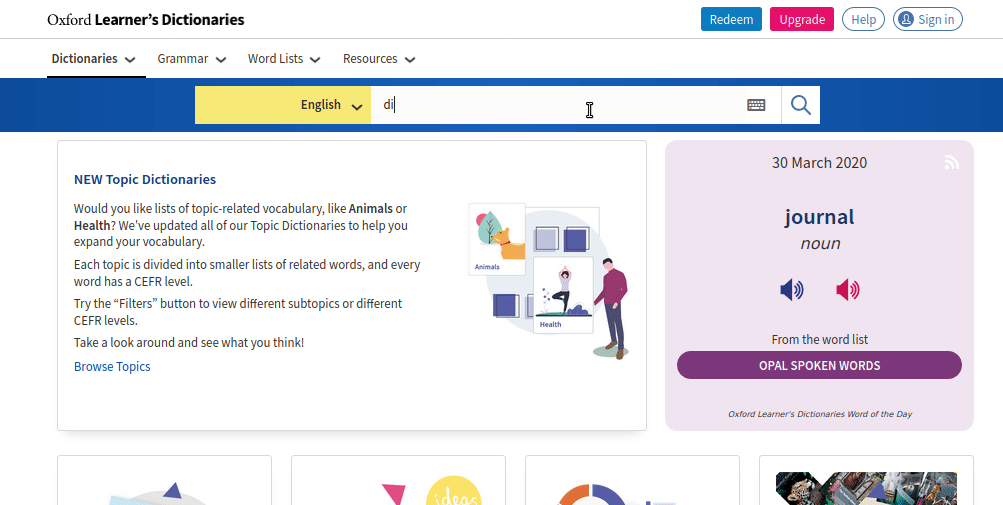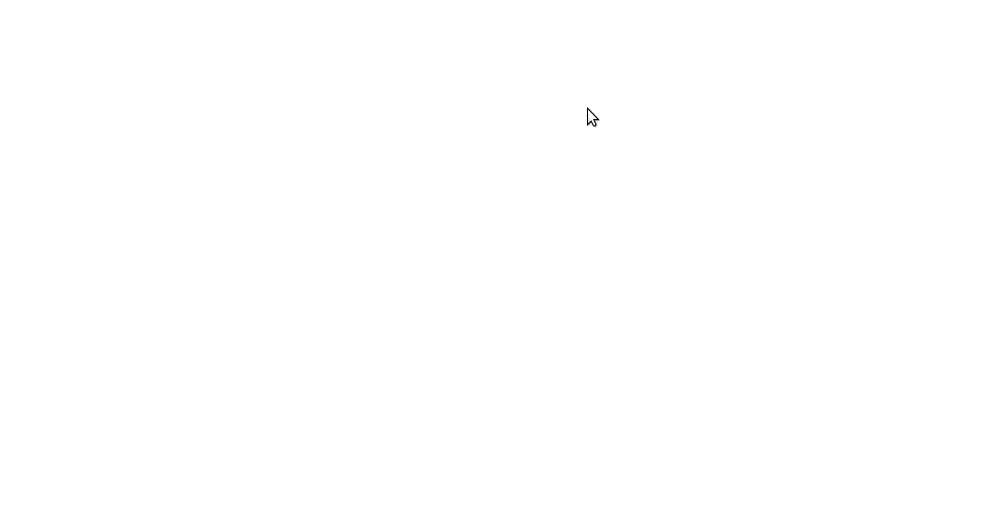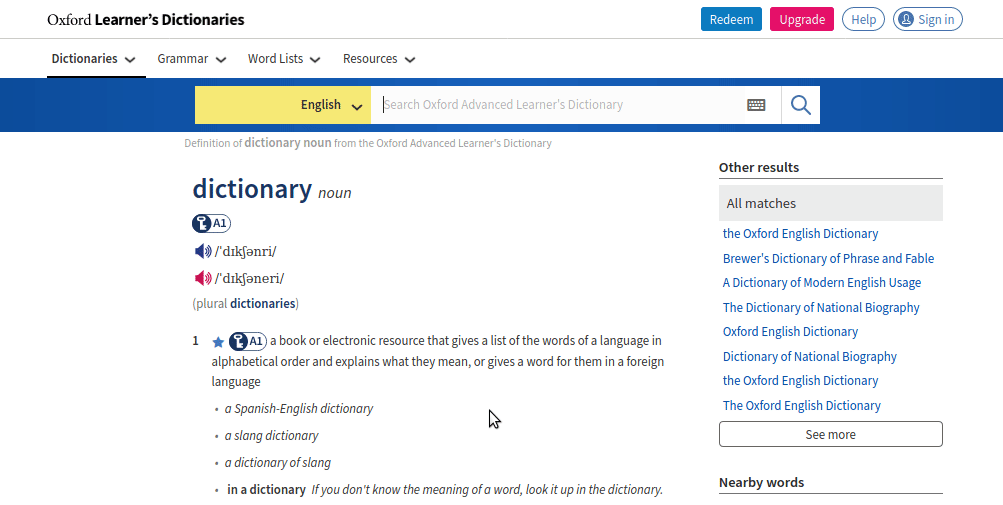
Now, let’s take a look at the page result link:
https://www.oxfordlearnersdictionaries.com/definition/english/dictionary?q=dictionaryIf you are slightly smart you should have already realized how this URL is composed.

The red portion is responsible for the magic trick. Whatever we write after the static portion will be interpreted by the website as a research, like the one described before. I have made some attempts, we can just add the word after the static portion and avoid the ?q=blabla thing. Having said that, let’s go back to our Python project. We are finally ready to define our function.
I decided to call it getMeaning, it will receive the unknown word as parameter and will be responsible of:
- Creating the link we will use for the request
- Making the HTTP request
- Receiving an HTML response
- Retrieving pronunciation and meaning
Let’s try to build our program step by step. Firstly, we will cover all the first three point mentioned before. I used a static string variable called word as parameter after have stripping and lowering it, this will be really useful when we will receive it as user input.
from bs4 import BeautifulSoup
import requests
from pprint import pprint
def getMeaning(text):
# create url
url = 'https://www.oxfordlearnersdictionaries.com/definition/english/' + text
# define headers
headers = { 'User-Agent': 'Generic user agent' }
# get page
page = requests.get(url, headers=headers)
# let's soup the page
soup = BeautifulSoup(page.text, 'html.parser')
pprint(soup)
word = 'Mathematics'
word = word.strip()
getMeaning(word.lower())In the following GIF image we can see the Python program in action.
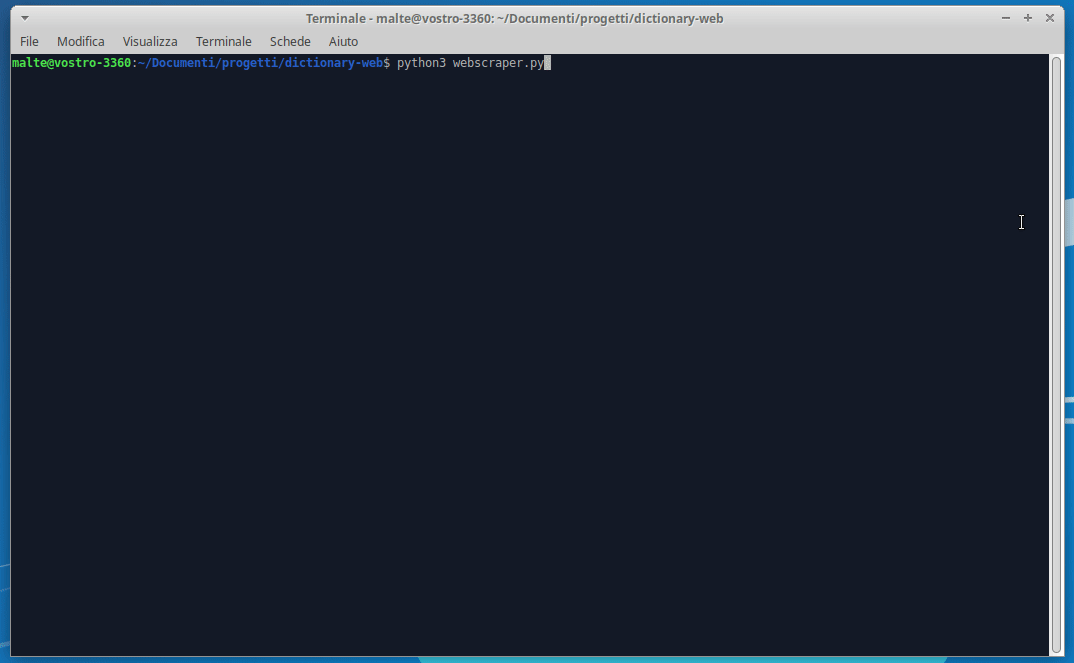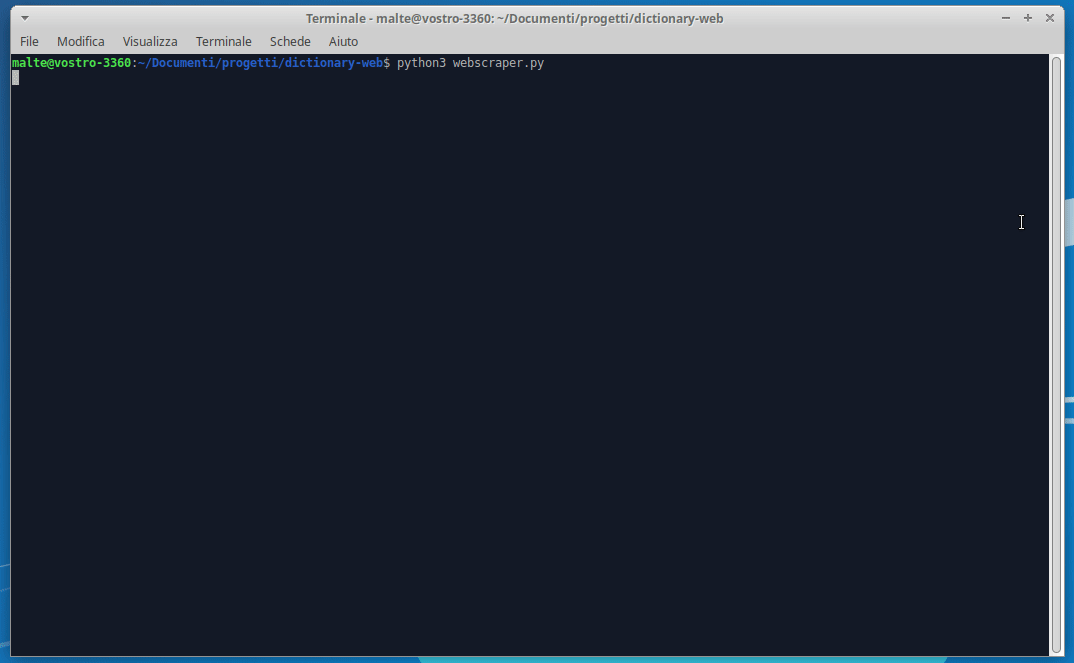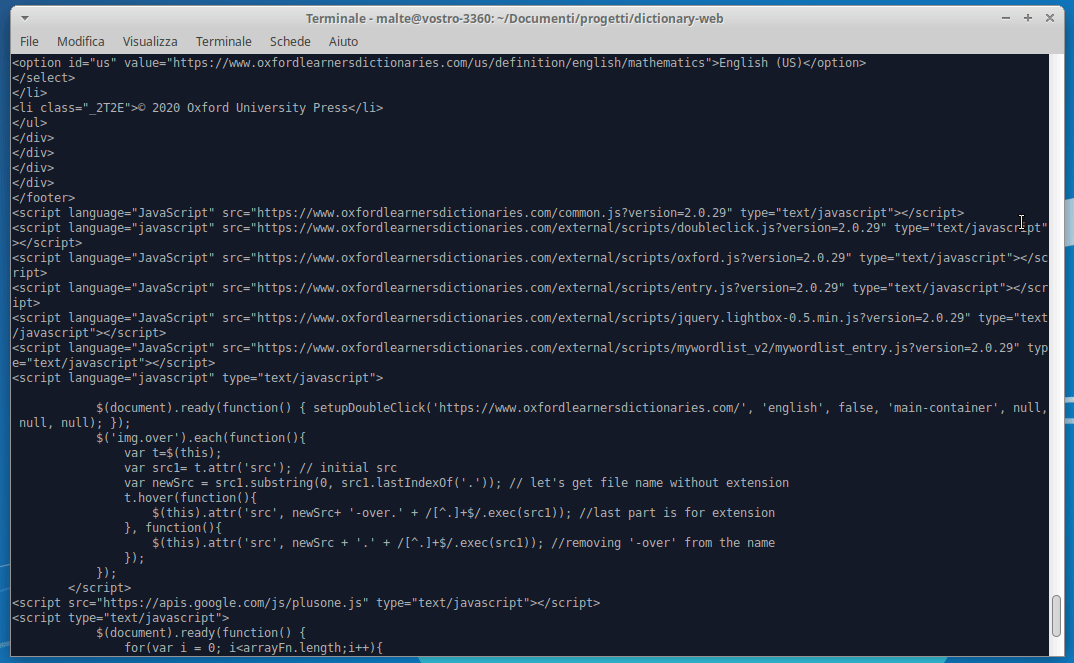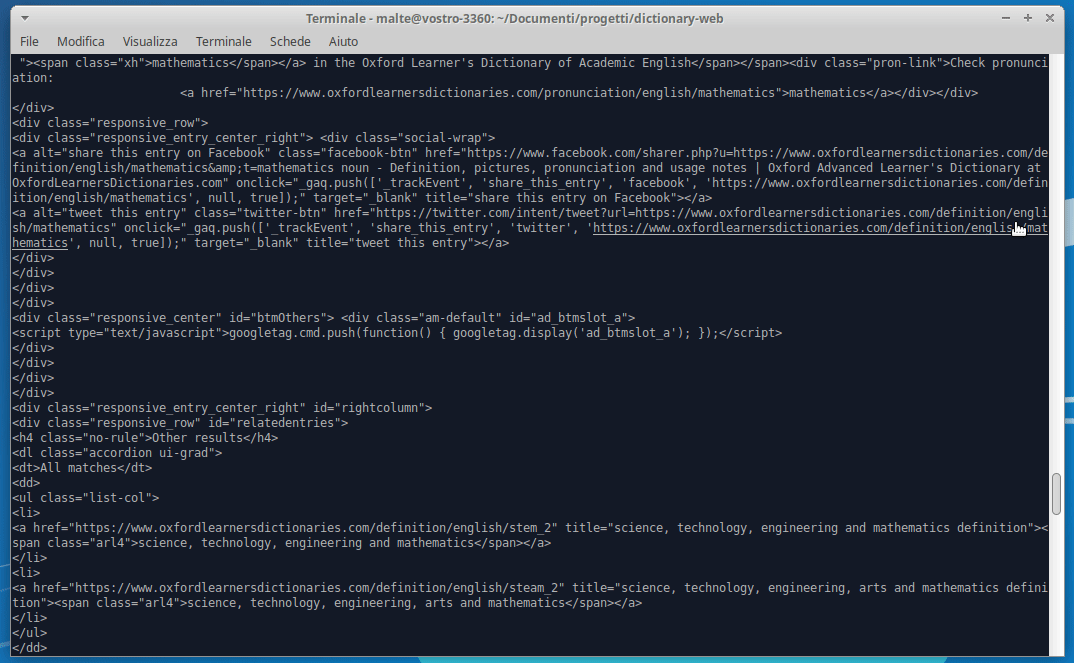
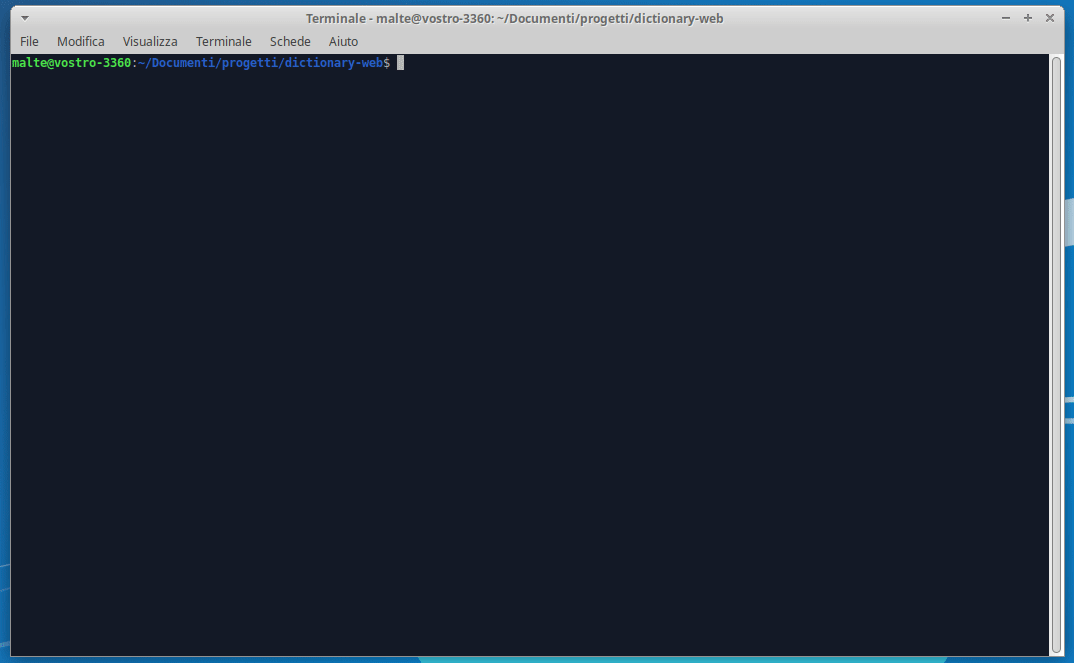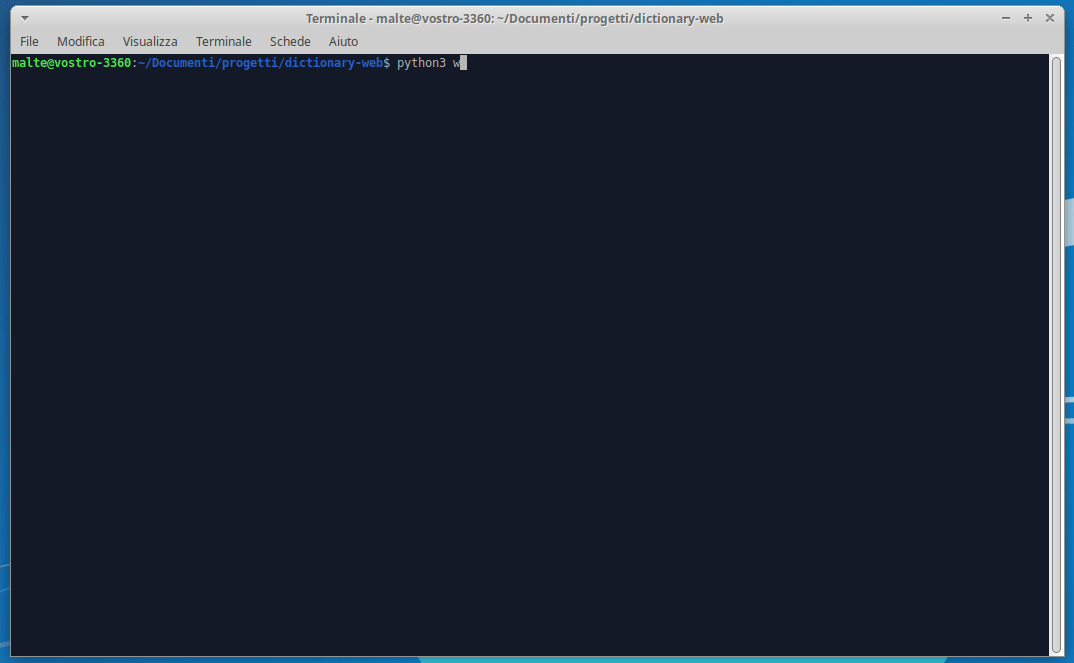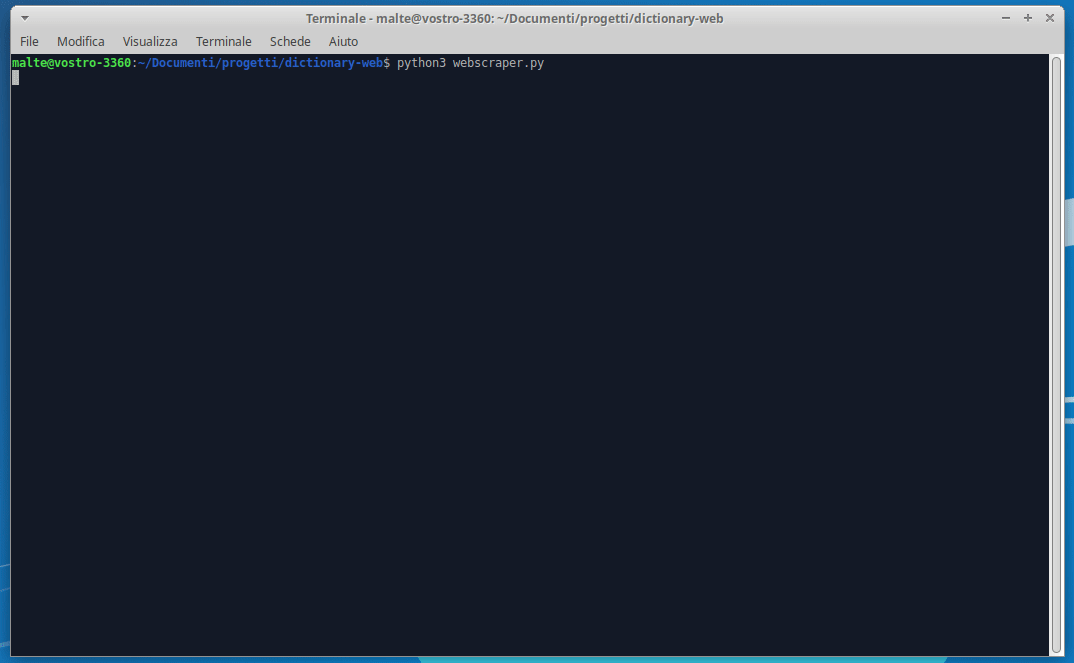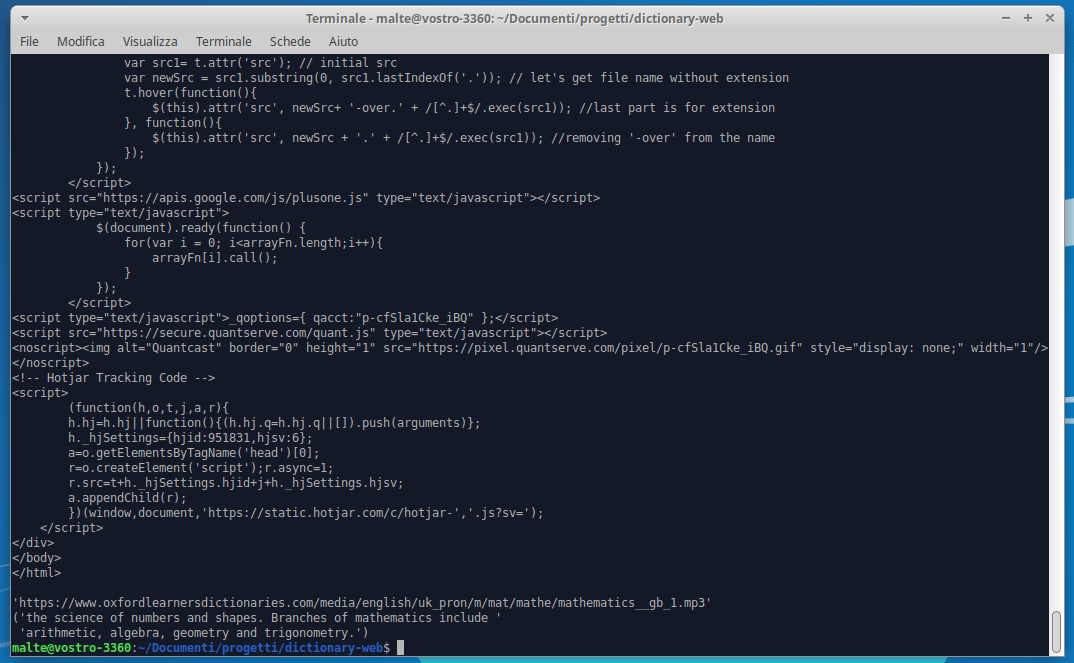
The pprint(soup) command at line 12 is logging the resulting HTML page of the GET request with link:
https://www.oxfordlearnersdictionaries.com/definition/english/mathematicsNow that we have the HTML result, we need to identify the point where the meaning and the pronunciation are located. To do so we can use the awesome function provided by our browser called “Inspect element” .
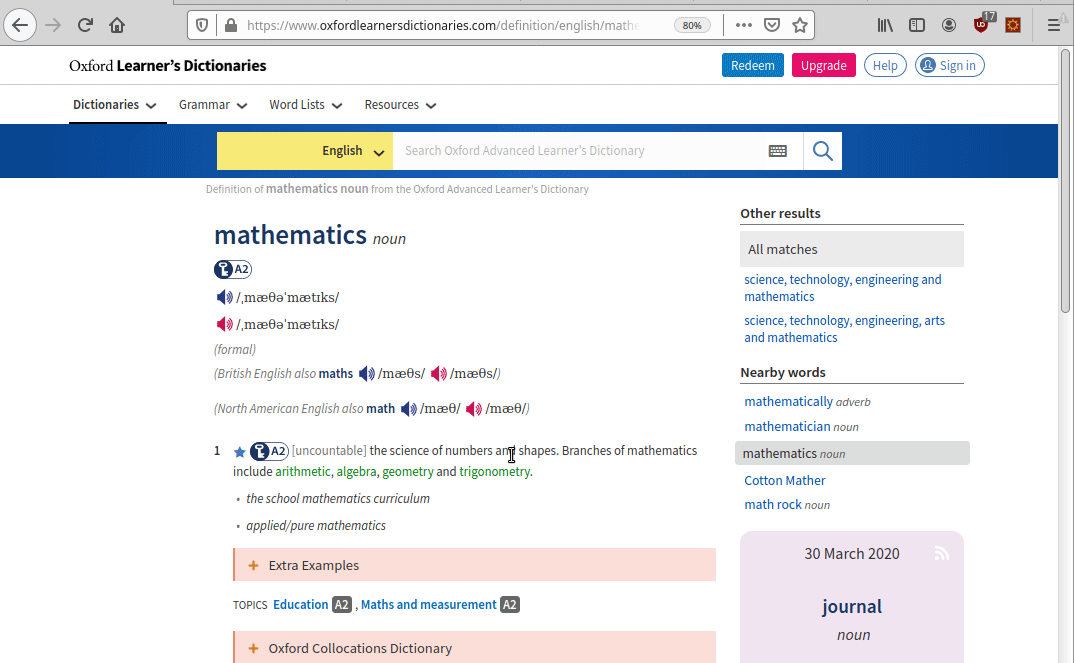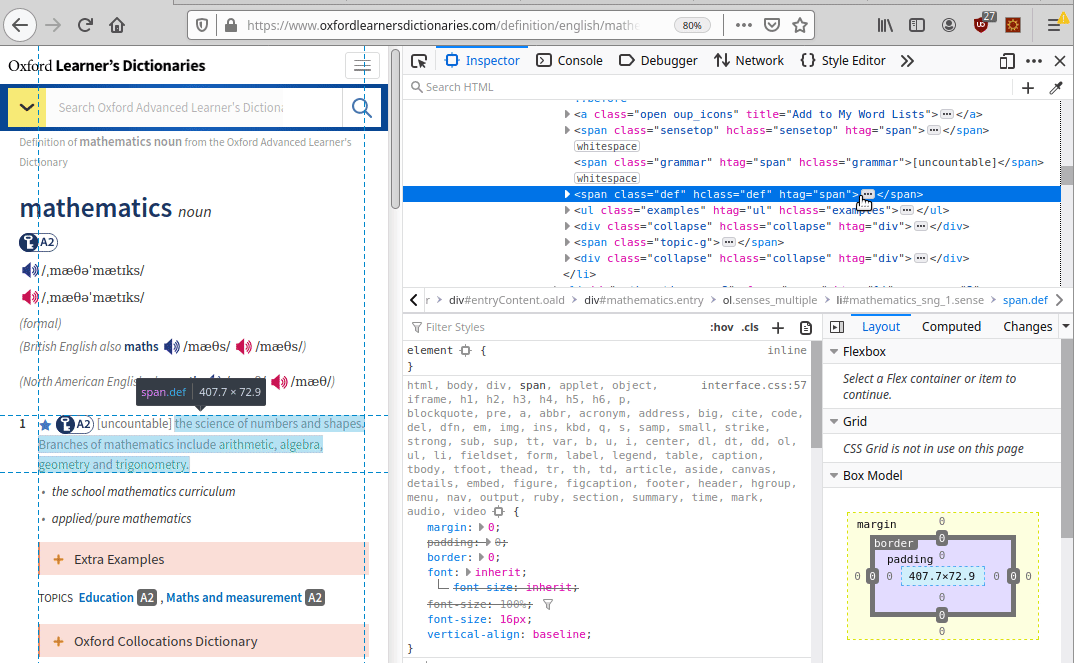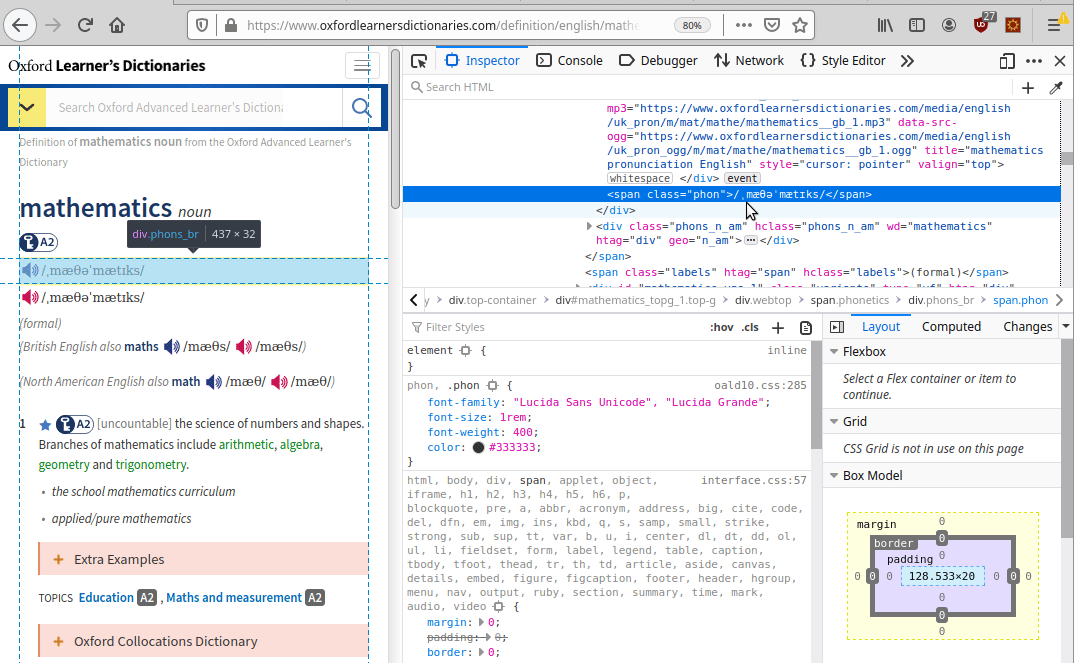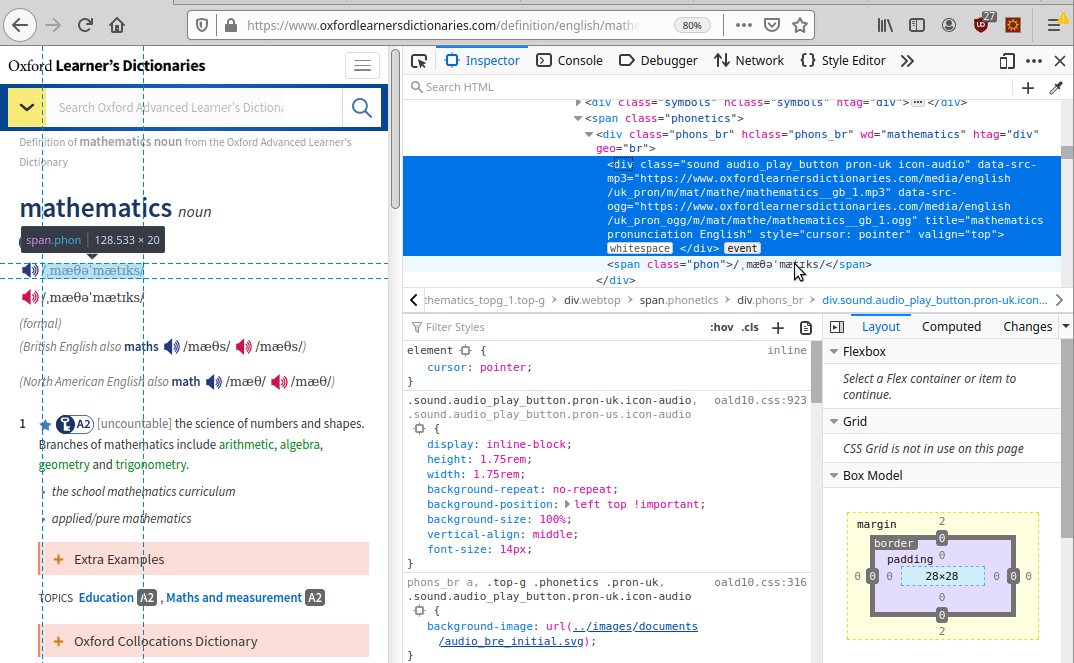
The meaning is located into a span with class=“def”, the pronunciation into a div with class=“sound audio_play_button pron-uk icon-audio”, this div has a property called data-src-mp3 that will provide us an mp3 file with the word pronunciation!
It is something more complicated but essentially similar to the following:
<span class="def" hclass="def" htag="span">Word meaning</span>
<div class="sound audio_play_button pron-uk icon-audio" data-src-mp3="https://www.oxfordlearnersdictionaries.com/media/english/uk_pron/m/mat/mathe/mathematics__gb_1.mp3"></div>To retrieve the text into the span and the link into the data-src-mp3 property, we will use the BeautifulSoup method called find. You can see the implementation after line 12.
from bs4 import BeautifulSoup
import requests
from pprint import pprint
def getMeaning(text):
# create url
url = 'https://www.oxfordlearnersdictionaries.com/definition/english/' + text
# define headers
headers = { 'User-Agent': 'Generic user agent' }
# get page
page = requests.get(url, headers=headers)
# let's soup the page
soup = BeautifulSoup(page.text, 'html.parser')
pprint(soup)
try:
# get MP3 and definition
try:
# get MP3
mp3link = soup.find('div', {'class': 'sound audio_play_button pron-uk icon-audio'}).get('data-src-mp3')
pprint(mp3link)
except:
pprint('Pronunciation not found!')
try:
# get definition
definition = soup.find('span', {'class': 'def'}).text
pprint(definition)
except:
pprint('Meaning not found!')
except:
pprint('Something went wrong...')
word = 'Mathematics'
word = word.strip()
getMeaning(word.lower())As excepted, this is the output with the meaning and the pronunciation (the link to the mp3 file):
HOW TO CREATE A TELEGRAM BOT
Creating a Telegram Bot is stupidly easy. Assumed that we already have a Telegram account, we need to start a chat with @BotFather that will immediately reply us with a command list. At this point we can type /newbot and follow its instructions.
Once we have decided the bot name and its username (make sure it ends in bot or _bot) we receive a token that will be useful in a following step to access the HTTP API.
I have decided to use a library called telepot. In order to convert our web scraper in a Telegram bot, let’s take a look at the following code. It is a basic async bot (for telepot projects), it just sends to the user the dump of the JSON received from the client.
We have to import some needed libraries: asyncio, telepot, telepot.aio and MessageLoop. Do not be afraid if you do not understand everything is written down here, it is not needed to understand all lines of code, the most important part is the handle function because it is exactly where we will implement our web scraping program.
import asyncio
import telepot
import telepot.aio
from telepot.aio.loop import MessageLoop
# This is the function we will modify
async def handle(msg):
# These are some useful variables
content_type, chat_type, chat_id = telepot.glance(msg)
# Log variables
print(content_type, chat_type, chat_id)
pprint(msg)
# Send our JSON msg variable as reply message
await bot.sendMessage(chat_id, msg)
# Program startup
TOKEN = 'paste here your token!'
bot = telepot.aio.Bot(TOKEN)
loop = asyncio.get_event_loop()
loop.create_task(MessageLoop(bot, handle).run_forever())
print('Listening ...')
# Keep the program running
loop.run_forever()This is our Python console in action when our bot receive a message:
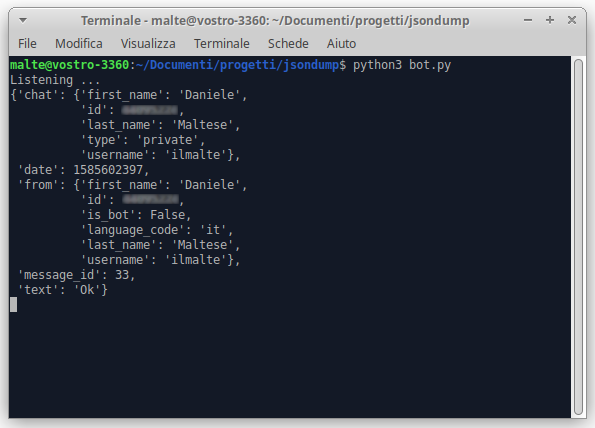
What we have to do now is integrate our web scraper in order to convert it into a telegram bot.
We start by adding the three missing libraries: pprint, BeautifulSoup and requests. At this point we can copy our getMeaning function and paste it there. Then we turn it into an async function and finally instead of printing the pronunciation link and the meaning in our console we will send them to the user, one as file and the other as text. I decided to define a global variable called chat_id (to reserve a better communication within the two functions) and checked the user input. Now we can call our async function from the handle and we are finally ready to test our Telegram bot!
import asyncio
import telepot
import telepot.aio
from telepot.aio.loop import MessageLoop
from pprint import pprint
from bs4 import BeautifulSoup
import requests
async def handle(msg):
global chat_id
# These are some useful variables
content_type, chat_type, chat_id = telepot.glance(msg)
# Log variables
print(content_type, chat_type, chat_id)
pprint(msg)
username = msg['chat']['first_name']
# Check that the content type is text and not the starting
if content_type == 'text':
if msg['text'] != '/start':
text = msg['text']
# it's better to strip and lower the input
text = text.strip()
await getMeaning(text.lower())
async def getMeaning(text):
# create url
url = 'https://www.oxfordlearnersdictionaries.com/definition/english/' + text
# define headers
headers = { 'User-Agent': 'Generic user agent' }
# get page
page = requests.get(url, headers=headers)
# let's soup the page
soup = BeautifulSoup(page.text, 'html.parser')
pprint(soup)
try:
# get MP3 and definition
try:
# get MP3
mp3link = soup.find('div', {'class': 'sound audio_play_button pron-uk icon-audio'}).get('data-src-mp3')
await bot.sendAudio(chat_id=chat_id, audio=mp3link)
except:
await bot.sendMessage(chat_id, 'Pronunciation not found!')
try:
# get definition
definition = soup.find('span', {'class': 'def'}).text
await bot.sendMessage(chat_id, definition)
except:
await bot.sendMessage(chat_id, 'Meaning not found!')
except:
await bot.sendMessage(chat_id, 'Something went wrong...')
# Program startup
TOKEN = 'paste here your token!'
bot = telepot.aio.Bot(TOKEN)
loop = asyncio.get_event_loop()
loop.create_task(MessageLoop(bot, handle).run_forever())
print('Listening ...')
# Keep the program running
loop.run_forever()Finally, we can see our Telegram bot in action!
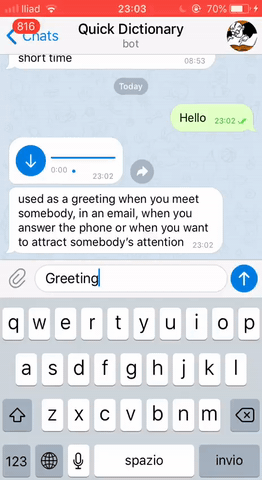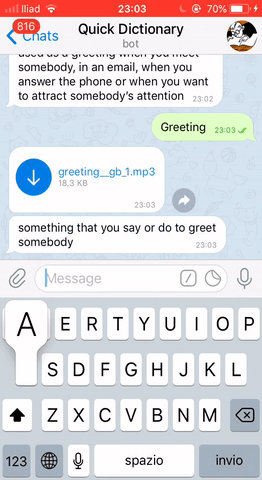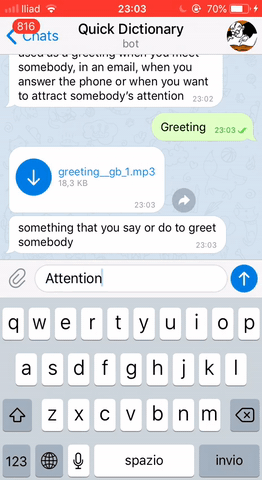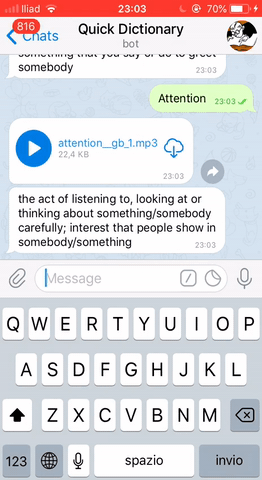
THAT’S IT!
All things considered, writing a simple web scraper Telegram bot using Python is really quick and interesting. I hope you enjoyed this reading and that this little project will intrigue your mind and will help you in creating something similar or even better. Feel free to contact me if you struggle in understanding something tricky or just to let me know what you developed.
Also, you can find the repository on my Github!